
Appen Contributes Private Benchmark Data to the Open ASR Leaderboard
We partnered with Hugging Face to add a private evaluation track to the Open ASR Leaderboard, high-quality ASR datasets kept off-limits from model developers to give the community a cleaner signal on real-world performance.
“When a measure becomes a target, it ceases to be a good measure.” Goodhart’s Law
As ASR models have improved, so have strategies for gaming leaderboards: training on public test sets, curating data that mirrors known evaluation distributions, optimizing for macroaverages rather than generalization. The Open ASR Leaderboard has been visited over 710K times since September 2023, that visibility is exactly what makes its public test sets a target.
Appen partnered with Hugging Face to contribute a private benchmark track: datasets held back from any public release, evaluated only by Hugging Face, and designed to measure genuine capability across accent diversity and speech styles. The full technical write-up is on Hugging Face: Adding Benchmaxxer Repellant to the Open ASR Leaderboard
The Datasets
Appen contributed seven English ASR evaluation sets covering scripted read speech and spontaneous conversational speech across four regional accents. Gender balance is near 50/50 across all splits a deliberate choice, since gender and accent gaps in benchmarks have historically masked real performance disparities.
All model outputs and reference transcripts are normalized using a Whisper-based normalizer that strips punctuation and casing and maps to American spelling the same normalization applied across the public sets.
How the Private Track Works
The private datasets live in a dedicated “🔒 Private data” tab on the leaderboard. Scores are aggregated with no individual split scores exposed, preventing optimization against specific providers or accents. Five aggregate metrics are reported:

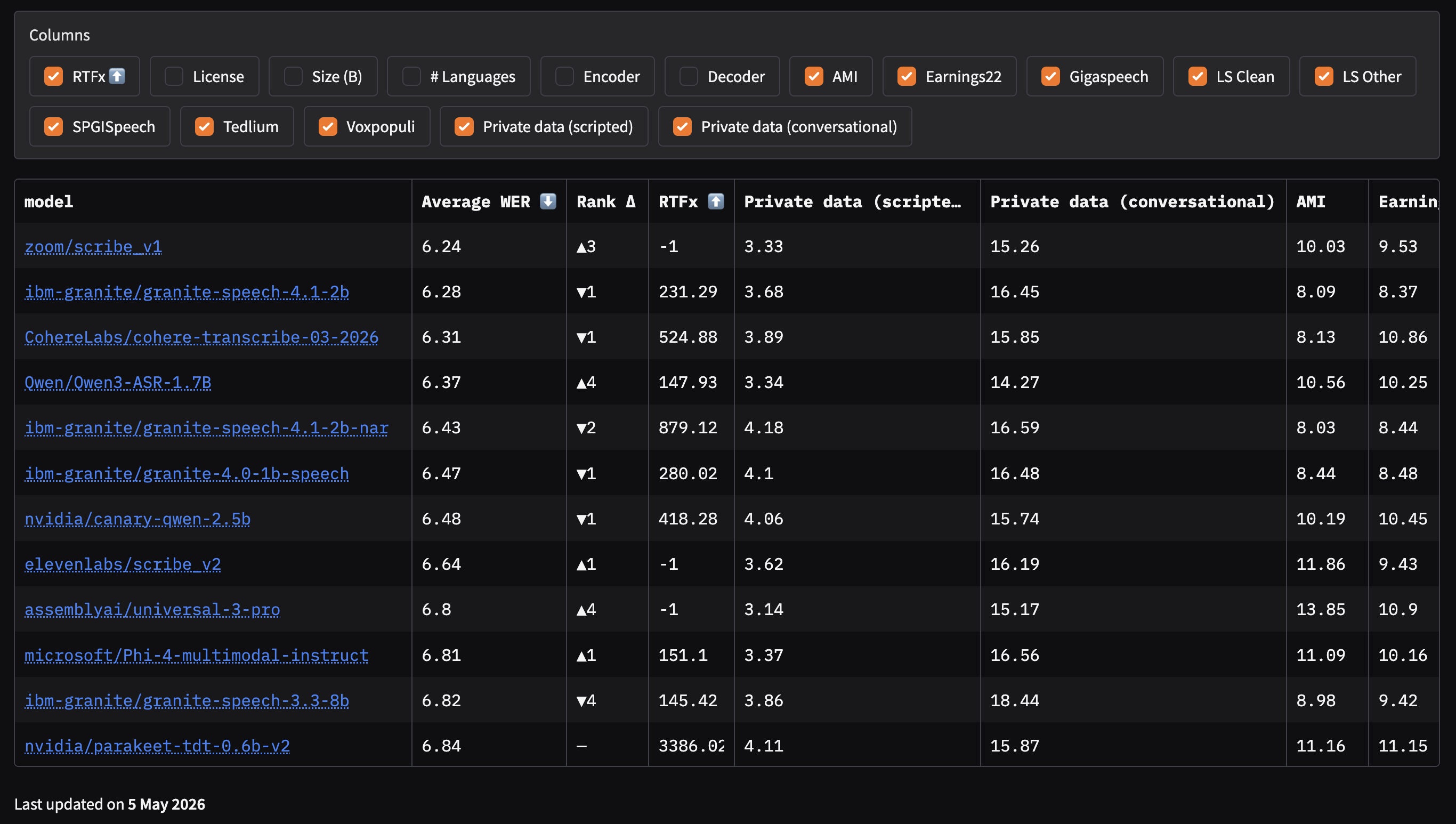
By default, private sets are excluded from the main leaderboard macroaverage. On the main leaderboard, two new toggle columns appear: Private data (scripted) and Private data (conversational).

When toggled on, they enter the macroaverage and the Rank Δ column shows how model ordering shifts relative to the public-only baseline.
What the Rankings Show
On the public-only leaderboard, ibm-granite/granite-speech-4.1-2b leads with a mean WER of 5.33.
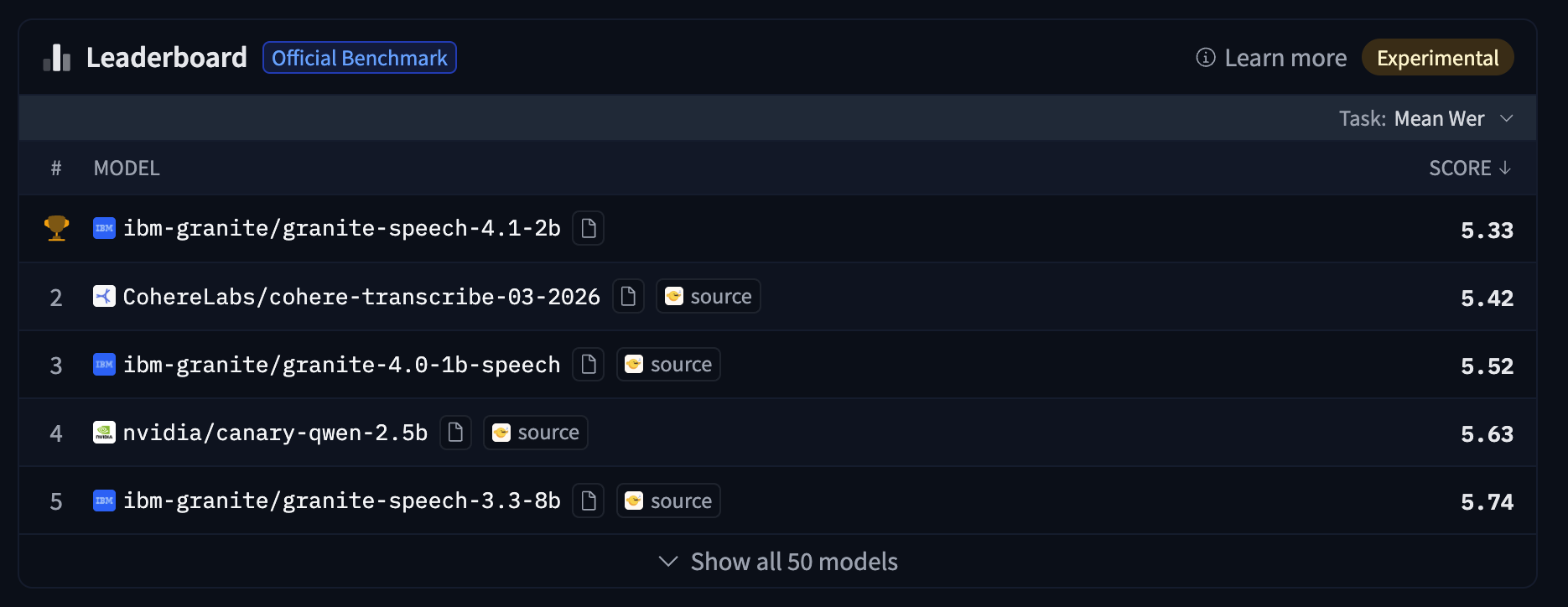
When Appen’s private datasets are toggled in covering Australian, Canadian, Indian, and American accents across scripted and conversational conditions zoom/scribe_v1 moves from #4 to #1 (Average WER 6.24, Rank Δ ▲3). The model that appeared strongest on public benchmarks drops one position. These shifts are not anomalies: they reflect what the private track is built to detect models whose public scores overstate their generalization.
The scripted/conversational gap is particularly diagnostic. Models optimized for clean read speech tend to perform well on public datasets (which skew toward controlled conditions) but show substantially higher WER on spontaneous conversational audio. The Avg Scripted vs. Avg Conversational split makes that gap explicit and model specific.
Why Private Datasets Protect the Benchmark
Public test sets can be used in training. Once a dataset is open, model developers can train it directly or curate similarly distributed data to inflate their scores. A leaderboard built entirely on public sets increasingly measures optimization ability.
Having multiple data providers distributes the structural advantage: a model trained on Appen data gains no edge on evaluation sets from other providers, and vice versa. And to prevent any provider’s data from distorting overall rankings, the private sets are excluded from the default macroaverage opt-in only.
How the Datasets Were Built
Contributors were recruited against all three attributes of the benchmark scope simultaneously: accent, environment, and device. Each passed a spoken-language assessment validating proficiency and accent, plus a recording-environment check confirming access to the specific device and acoustic setting required.
Scripted and conversational speech followed separate protocols. Scripted scripts target specific phoneme, named entity, number, and domain vocabulary distributions. Conversational prompts are designed to elicit disfluencies, turn-taking, and informal registers, not cleaned-up speech.
Every recording pass two QA gates before transcription: automated checks (sample rate, codec, signal-to-noise ratio) and a human verification step. Files that fail either are flagged for re-recording.
Transcription combines automated quality scoring with human post-editing. Segments below the quality threshold go to post-editors for correction. All transcripts are then reviewed by senior auditors against a style guide, with speaker attribution and turn boundaries validated for multi-speaker recordings.


Full technical details: huggingface.co/blog/open-asr-leaderboard-private-data