
Benchmarking Subquadratic’s latest model & SSA Kernel
56× faster than FlashAttention-2 at 1M tokens. Independent efficiency, retrieval, and SWE-Bench benchmark of sparse self-attention. Download the full report.
The transformer attention mechanism is a fundamental bottleneck in the industry. At long context lengths, its O(n²) cost becomes the dominant constraint on what's deployable due to the sheer compute of attending over every token pair. While the industry has largely accepted this limitation, Subquadratic's Sparse Self-Attention (SSA) kernel claims to break that curve, replacing full dense attention with a learned sparse routing pass that scales linearly with context length.
That's a strong claim. Appen independently evaluated Subquadratic's latest model release across four benchmarks of efficiency profiling, long-context retrieval, and real-world code intelligence to determine whether the numbers hold at production-relevant context windows.
This post covers selected highlights. The full report including per-run profiler data, measured FLOP validation, and signed attestations is available to download below.
The Efficiency Case: Quadratic vs. Linear in Practice
Standard full self-attention scales as O(n²): double the context length, quadruple the compute. This is not a constant-factor problem it is a structural one that compounds quickly. At 1M tokens, the theoretical compute burden of dense attention is ~64× that of 128K. The practical consequence is that very long contexts simply aren't viable for most production deployments using unmodified transformer architectures.
SSA addresses this by replacing the full attention pass with a selection mechanism identifies the most relevant token pairs and routes compute only to those. The claimed outcome is linear scaling: each doubling of context doubles rather than quadruples compute.
What the Data Shows
Appen measured end-to-end wall clock latency for SSA and FlashAttention-2 (FA2) at four context lengths on NVIDIA B200 hardware (CUDA 13.0, PyTorch 2.11.0, bfloat16). Results are the mean of 5 timed runs after 3 warmup iterations.
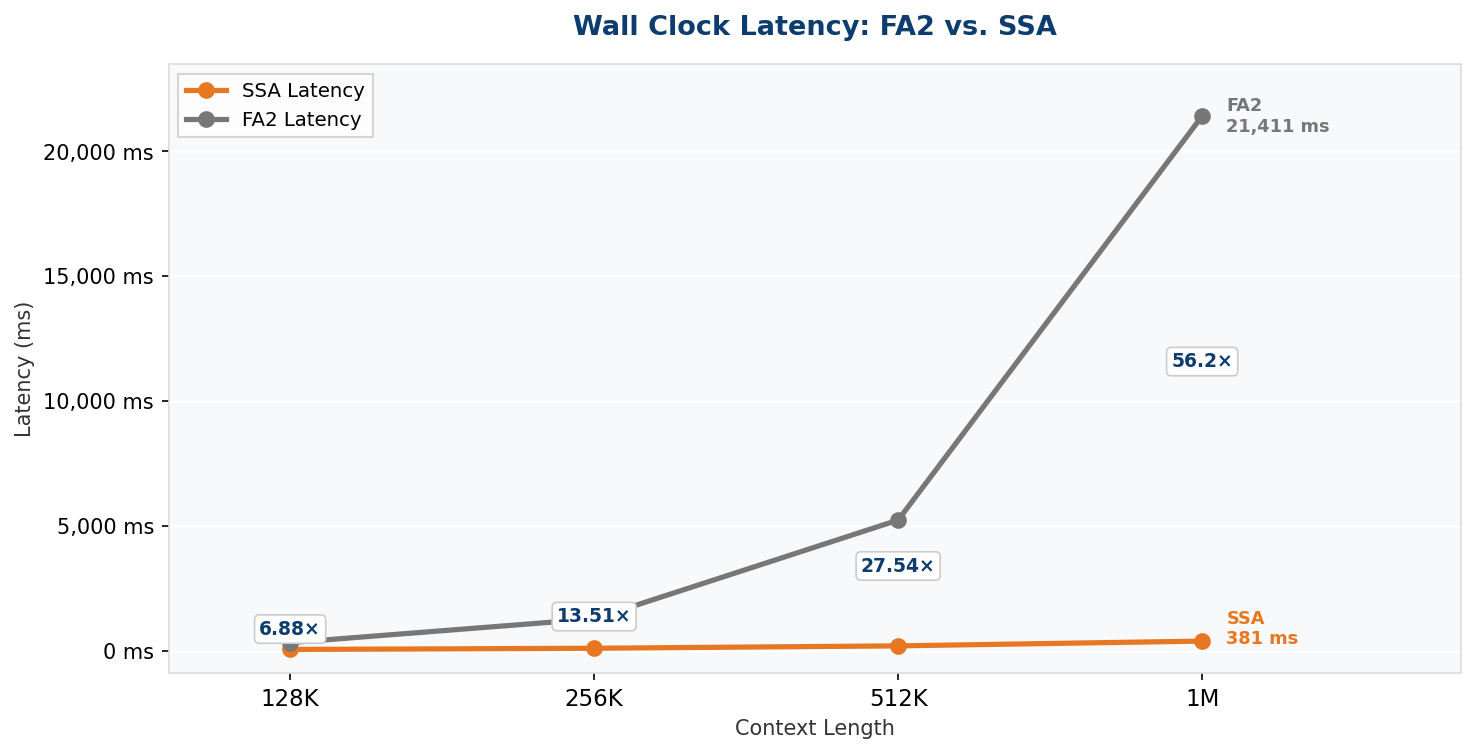
FA2 follows the theoretical O(n²) curve almost exactly. SSA follows a linear curve with near-perfect fidelity latency growth of 7.95× at an 8× context increase is a near-exact match to O(n) behaviour. The 56.2× end-to-end speedup at 1M tokens is not a cherry-picked figure: it is the natural consequence of two architectures diverging along their respective complexity curves.
At 1 million tokens, SSA completes in 381 ms. The equivalent FA2 pass takes 21.4 seconds a 56× wall clock difference that widens predictably with every additional token.
FLOP Efficiency
Wall clock time conflates compute with hardware effects. FLOP counts provide an architecture-independent measure of actual computational work. Using the standard FlashAttention / MLPerf formula and validated against torch.profiler measurements (matching theory to within 0.7–3.9% across all tested lengths), the FLOP reduction at 1M tokens is 62.8×:

The linearity of SSA's FLOP growth is notable: each context doubling approximately doubles SSA's FLOPs, confirming the architectural claim holds at the compute level not just at the wall clock level. The full report includes per-run profiler data and the torch.profiler validation methodology.
Long-Context Retrieval Quality: Does Efficiency Trade Off Against Accuracy?
Efficiency gains at long contexts are only meaningful if model quality holds. Sparse attention architectures have historically traded some retrieval accuracy for compute savings; the question is how much, and what context lengths. Appen evaluated retrieval quality across two benchmarks spanning 128K and 1M token windows.
RULER at 128K Tokens
RULER (Retrieval Under Long-context Evaluation Regimen) is a publicly available NVIDIA benchmark covering singleand multi-hop question answering, word extraction, variable tracking, and multi-needle retrieval. All tasks were run at 131,072 tokens with 100 samples per task. Question answering and extraction tasks were evaluated using Claude Opus 4.6 as LLM judge an established evaluation methodology that captures semantically correct answers exact-string matching would penalise.
Perfect scores on all single-needle retrieval and structural tracking tasks confirm reliable information extraction throughout a 128K context. Multi-key retrieval shows the expected degradation as the number of simultaneous targets increases a well-documented pattern across all evaluated architectures, noted explicitly in the RULER paper itself. This is a benchmark stress-test by design, not an SSA-specific limitation.
MRCR at 1 Million Tokens
MRCR (Multi-needle Retrieval in Context at Range) is the harder test. Appen evaluated exclusively on the 8-needle tier requiring simultaneous retrieval of eight distinct targets on the largest bucket of inputs in the MRCR dataset, from 524,288 to 1,048,576 tokens. This is a context length that is computationally unreachable for most dense-attention deployments.
86.2% on the hardest retrieval tier at 1M tokens is a substantive result. The error pattern is bimodal: the model either retrieves all eight needles correctly or misses the pass entirely, suggesting an all-or-nothing retrieval behavior. The full data breakdown and per-sample analysis are in the report.
Real-World Code Intelligence: SWE-Bench Verified
SWE-Bench Verified presents actual GitHub issues from curated open-source Python repositories. The model must produce a code patch that resolves the issue and passes all existing tests without regressions. There is no partial credit it either resolves or it doesn't. Extended thinking was enabled to reflect realistic agentic deployment conditions.
81.8% of real GitHub issues resolved passing all repository tests places Subquadratic among the top performers on SWE-Bench Verified at the time of evaluation. Combined with the efficiency results, this signals that the sparsity architecture does not impose a quality penalty on complex, multi-step reasoning tasks.
Independence and Methodology
Appen operated with full independence throughout this assessment. For benchmarks, access was scoped to Subquadratic's API endpoints and authentication keys only; no model weights, training data, fine-tuning configurations, or benchmark ground-truth labels were provided in advance. For wall clock and FLOPs analyses, Appen got access to the key algorithm code, did a code review, and was able to run side-by-side tests. All measurements reflect authentic, uninfluenced model performance.
The evaluation was led by Jeanine Sinanan-Singh (Director of GenAI Research) and Sergio Bruccoleri (VP, Operations). The full technical report includes the complete methodology, hardware configuration, per-run timing data, torch.profiler validation outputs, and signed attestation of independence.
What's in the Full Report
This landing page covers the headline findings. The complete technical report includes:
- Per-run wall clock measurements (5 timed runs, 3 warmup iterations) at all four context lengths
- torch.profiler FLOP validation with match analysis against theoretical predictions (0.7–3.9% variance)
- Full RULER per-task breakdown: all 13 task types, 100 samples each
- MRCR per-sample results and error pattern analysis at 1M tokens
- SWE-Bench Verified pass/fail breakdown with extended thinking configuration
- Signed attestation of evaluation independence and methodology
Download the Full Benchmark Report
Complete methodology, profiler data, per-task breakdowns, and signed attestation of independence.