
LLM Hallucinations: Why Models Make Mistakes & How to Fix Them
Explore new insights on why language models hallucinate. Learn how Appen addresses AI hallucinations with quality data, human feedback, and evaluation strategies.
It’s a well-known fact that large language models (LLMs) hallucinate. But why?
LLMs are known to make confident statements that turn out to be false, known as hallucinations. These errors undermine trust, introduce AI safety risks in sensitive domains like healthcare and law, and limit adoption in enterprise settings. Mitigating errors is essential to successful deployment. So, let’s explore the latest insights into how and why these hallucinations happen, as well as what can be done to prevent them. At Appen, we’re taking a close look at these findings and connecting them to the practical data and LLM evaluation strategies organizations need to build more trustworthy AI.
A recent paper from OpenAI, Why Language Models Hallucinate (Kalai et al., 2025), sheds light on the statistical roots of this persistent phenomenon, which plagues even the most state-of-the-art systems. When prompted for the title of Kalai’s well-known PhD dissertation, for example, several popular models confidently gave wrong answers. This anecdote resonates with anyone who has tried using LLMs for research: models often invent sources, merge unrelated papers, or hallucinate baseless facts.
So, why do language models hallucinate?
The OpenAI team argues hallucinations are simply a natural outcome of how LLMs are trained and evaluated.
- Pretraining errors are inevitable. Even with perfect training data, the mathematics of pretraining predicts a baseline error rate. Hallucinations are a statistical side effect of minimizing prediction loss.
- Post-training rewards guessing. Models are scored on binary metrics—right or wrong. Because “I don’t know” is scored as zero, bluffing is almost always the optimal strategy. Like students on multiple-choice exams, LLMs maximize their score by guessing when uncertain.
- Benchmarks amplify the problem. Popular evaluations such as MMLU, GPQA, and SWE-bench overwhelmingly penalize uncertainty. A model that always “guesses” can outperform a model that honestly admits when it doesn’t know.
This creates what the authors call an epidemic of penalizing uncertainty. In practice, models learn to prioritize being plausible over being correct.
The phenomenon of “teaching to the test” makes it all the more important for us to critically evaluate LLMs with custom benchmarks. In our recent work on multilingual LLM translation, we sought to address this exact problem by creating our own evaluation framework to assess top multilingual models for the cultural resonance of their translations, not just token-level accuracy. How different would these results be if the models could simply say “I don’t know?” instead of confidently presenting a guess?
Consider some common LLM hallucination examples:
- Summarizing papers: Researchers report that LLMs often invent results or merge details from different studies when asked to summarize academic work.
- Medical settings: In trials, models have hallucinated treatment options that don’t exist, posing obvious safety risks.
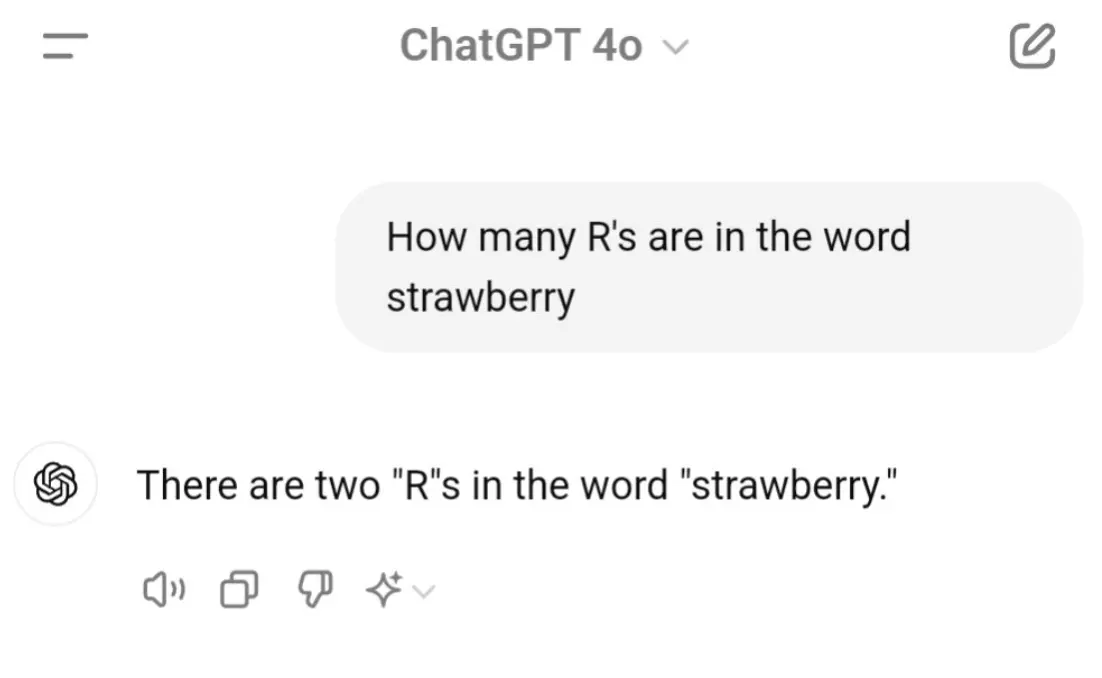
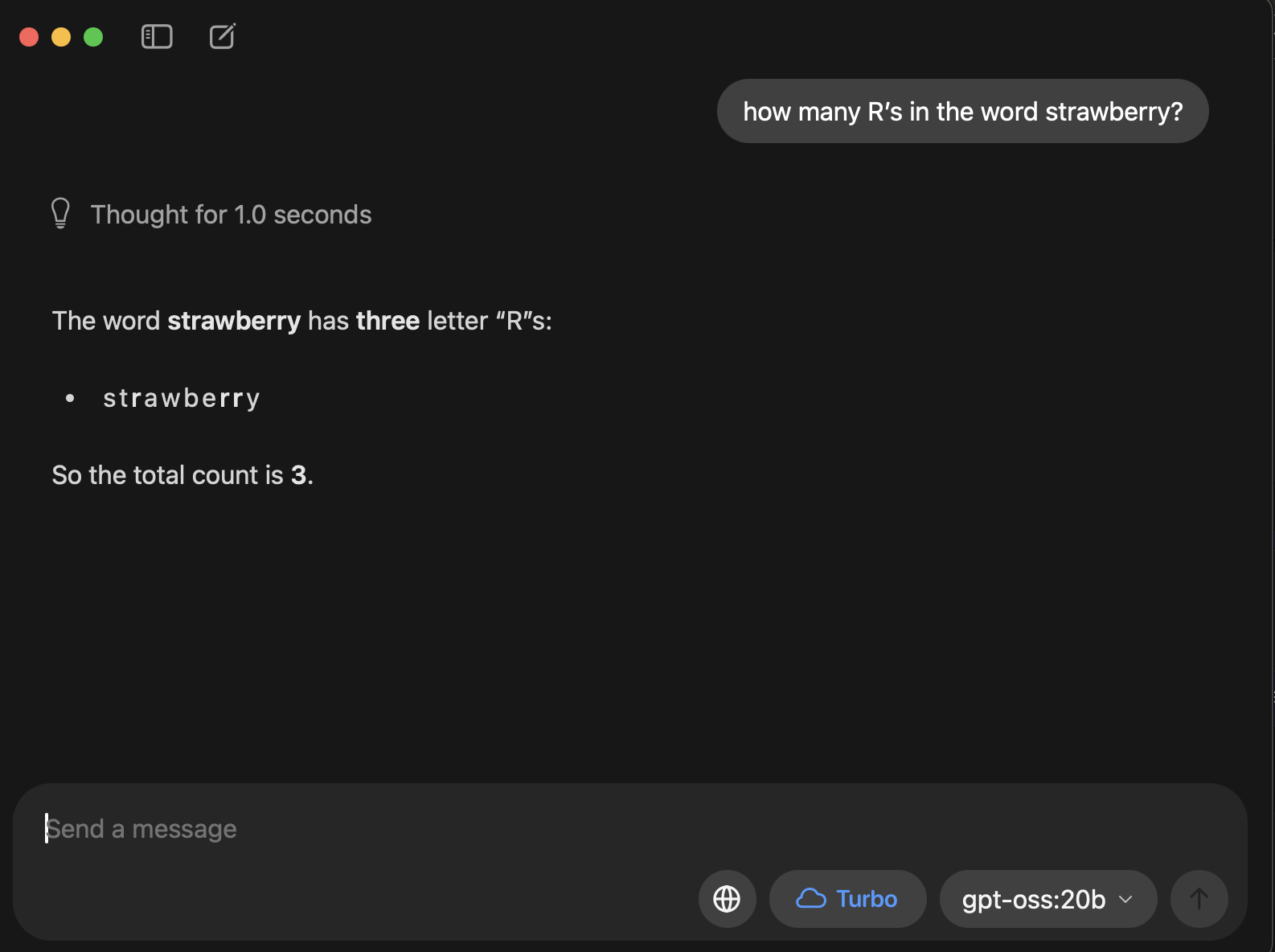
- Counting letters: When asked, “How many Ds are in DEEPSEEK?” some models confidently responded “2” or “3,” even though the correct answer is “1.” Others produced numbers as high as 7. Encouragingly, we’ve already seen improvements across recent GPT models.
The Risks of Hallucination
What these examples share is overconfidence; the model delivers the wrong answer with conviction. Unchecked, hallucinations pose serious risks such as:
- E-Commerce: Errors in logistics or catalogs can cause major retail AI breakdowns.
- Finance: Incorrect investment guidance or compliance errors have big downstream impacts.
- Customer service: Chatbots “make up” policies and negatively impact customer experience, trust, and business outcomes.
- Legal & government: Misleading references or fabricated precedents (more on that later) have serious legal implications.
- Some of the most striking examples of LLM hallucinations have surfaced not in research labs, but in courtrooms.
Some of the most striking examples of LLM hallucinations have surfaced not in research labs, but in courtrooms.
Case 1: ChatGPT in the Avianca Airlines Lawsuit (2023)
In one of the first high-profile AI hallucination cases, a law firm representing a passenger in a personal injury lawsuit used ChatGPT to prepare a filing and cited six fictitious cases. The lawyers were fined $5,000 for what the court described as “acts of conscious avoidance and false and misleading statements” (Merken, 2023). The attorneys relied on ChatGPT for legal research and then stood by the fake citations even after they were challenged. The judge emphasized that lawyers have a “gatekeeping role” to verify the accuracy of their filings, reinforcing the need for human oversight.
Case 2: Anthropic’s Claude in a Copyright Dispute (2025)
Two years later, Anthropic faced a similar embarrassment in its ongoing copyright battle with music publishers. When it came to light that a recent filing contained a fictional citation, Anthropic’s lawyers apologized, calling it “an honest citation mistake and not a fabrication of authority” and claiming the error was missed in manual review (Zeff, 2025).
Together, these incidents show how hallucinations can escape into high-stakes domains. In law, fabricated citations can not only derail cases but also damage professional reputations, incur sanctions, and erode trust in both legal and AI systems.
Mitigating Hallucinations and Building Trustworthy AI
OpenAI’s findings give us new insights into improving LLMs and mitigating errors. When we understand that hallucinations are a predictable outcome of today’s training and evaluation methods, this creates an opportunity for growth. Progress depends on shifting the incentives.
This means redesigning LLM benchmarks so models aren’t rewarded for bluffing. A system that admits “I don’t know” should not score worse than one that invents a confident lie. It also means measuring calibration and tracking whether a model’s confidence matches reality so we can reward abstention as a responsible answer, not a failure.
Equally important is the role of human-in-the-loop As we saw with the legal examples, expert review remains the best safeguard. Robust QA enables us to spot subtle errors, provide corrective feedback, and guide models toward more reliable behavior. Since AI is not static, continuous feedback loops are essential: monitoring outputs, catching drift, and fine-tuning with updated, high-quality data.
These directions echo a broader call across the AI community: to build models that are as powerful as they are accountable. In practice, this requires the unglamorous work of diverse AI training data, , careful evaluation design, and ongoing oversight—the very foundations of trustworthy AI.
Science shows why hallucinations persist. The challenge now is to realign our benchmarks, data pipelines, and expectations so that honesty becomes the standard.
Key Takeaways
- Treat hallucinations as systemic, not incidental. Long-term solutions require end-to-end investment across the AI lifecycle.
- Reevaluate how you evaluate. Build benchmarks that reward accuracy and abstention, not bluffing.
- Keep humans in the loop. Leverage expert oversight to validate outputs and catch errors before they compound.
- Prioritize high-quality data. Diverse, domain-specific training data ensures models learn from sources representative of your use case.
- Maintain continuous feedback loops. Monitor, correct, and fine-tune models as they encounter new inputs.
References
Merken, S. (2023, June 22). New York lawyers sanctioned for using fake ChatGPT cases in legal brief. Reuters. https://www.reuters.com/legal/new-york-lawyers-sanctioned-using-fake-chatgpt-cases-legal-brief-2023-06-22/
Kalai, A. T., Nachum, O., Vempala, S. S., & Zhang, E. (2025, September 4). Why language models hallucinate. OpenAI. https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
Zeff, M. (2025, May 15). Anthropic’s lawyer was forced to apologize after Claude hallucinated a legal citation. TechCrunch. https://techcrunch.com/2025/05/15/anthropics-lawyer-was-forced-to-apologize-after-claude-hallucinated-a-legal-citation/